L’objectif de la ville de Seattle est d’être neutre en émissions de carbone en 2050.
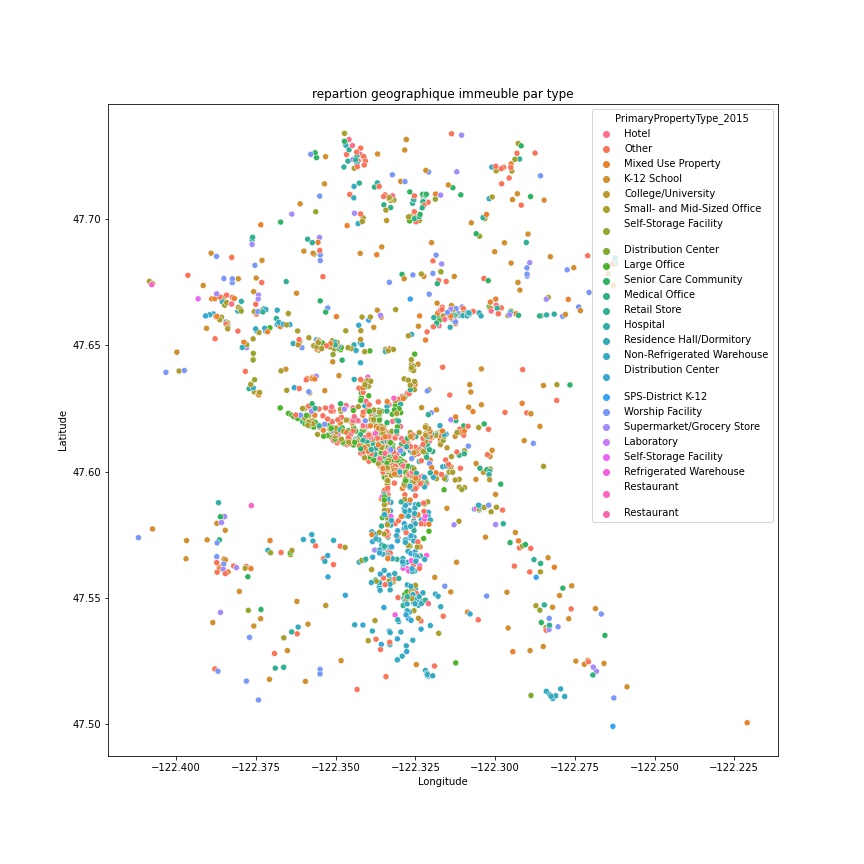
Pour cela des relevés par des agents ont été exécutés en 2015 et 2016. Ces relevés sont fastidieux et demandent beaucoup de travail, la ville voudrait tenter de prédire les données pour les bâtiments non destinés à l’habitation et non encore relevés.
Nous allons chercher à prédire la consommation d’énergie et la quantité de CO2 émis. Nous allons aussi évaluer l ’intérêt du calcul du score « ENERGY STAR » pour prédire les émissions de gaz à effet de serre.
Ces prédictions devront se baser sur les données déclaratives du permis d’exploitation commerciale (taille et usage des bâtiments, date de construction).
Le score « ENERGY STAR » étant calculé en fonction de la consommation d’énergie, de l’utilisation du bâtiment, on pourrait envisager d’utiliser la prédiction de consommation d’énergie pour prédire l’émission de CO2. Nous ferons une comparaison avec et sans cette donnée.
Déroulement du projet
Ce projet nous permet de rentrer de plein pied dans le Machine Learning.
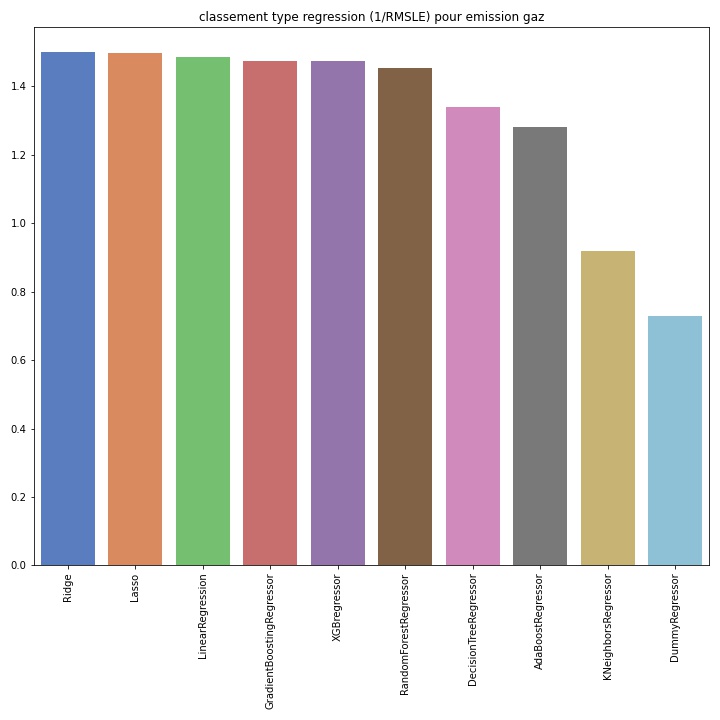
En effet, j’ai du faire une Analyse exploratoire des données, transformer les variables en les passant au log, entrainer différents types d’algorithmes, les optimiser et les comparer.
J’ai pu tester ainsi :
Régression linéaire, Régression Ridge et Lasso
DecisionTree
KNeighbors
RandomForest
ADABoost
GradientBoost
XGBOOST
Compétences acquises
Mettre en place le modèle d’apprentissage supervisé adapté au problème métier
Évaluer les performances d’un modèle d’apprentissage supervisé
Adapter les hyperparamètres d’un algorithme d’apprentissage supervisé afin de l’améliorer
Transformer les variables pertinentes d’un modèle d’apprentissage supervisé