Le projet P3 nous propose d’analyser un gros dataset (OpenFoodFact) qui est le point de départ de l’application YUKA. Ce dataset contient plus de 1 600 000 lignes de 184 variables. Le but est de proposer une application utilisant ces données.
Déroulement du projet
J’ai cherché d’abord les incohérences et abérations dans le dataset, ainsi que le doublons. J’ai alors utilisé un algorithme KNN (K Nearest Neighbors) pour remplacer les valeurs manquantes du Nutriscore.
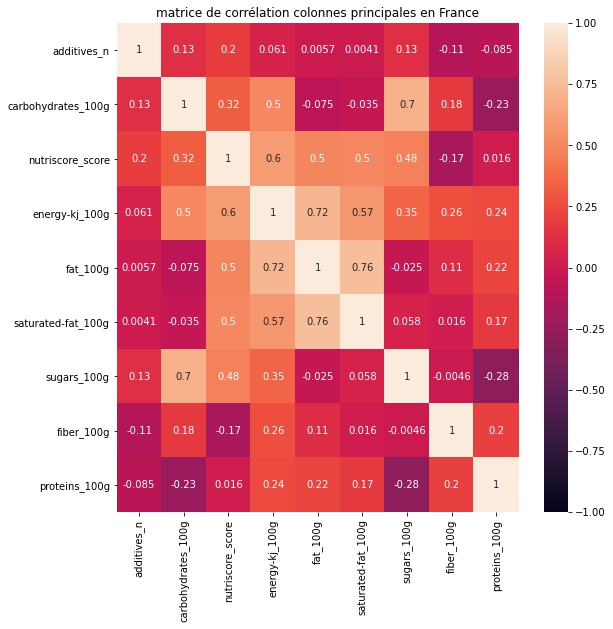
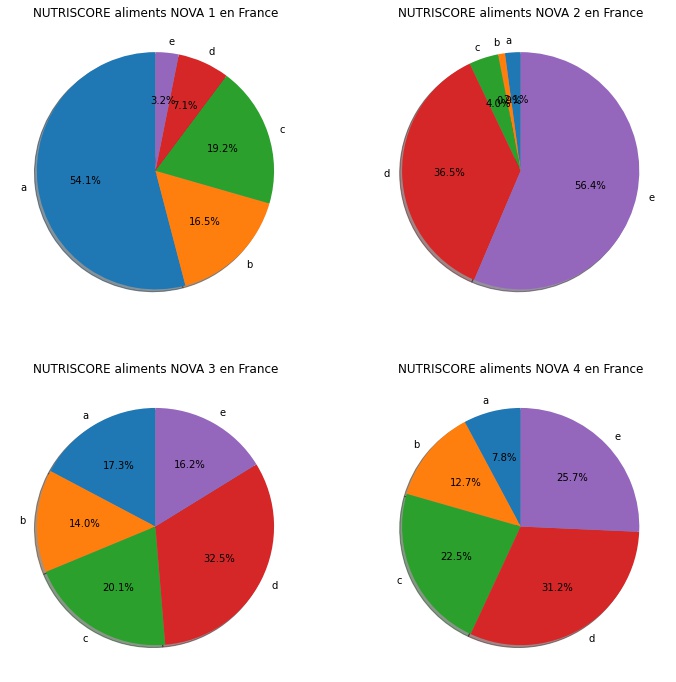
Une analyse des variables pertinentes et de corrélation avec le Nutriscore ont permis de limiter les variables. Une recherche à la fin permet de proposer des produits de remplacement.
Compétences acquises
Effectuer des opérations de nettoyage sur des données structurées
Communiquer ses résultats à l’aide de représentations graphiques lisibles et pertinentes