Construire un modèle de scoring qui donnera une prédiction sur la probabilité de faillite d’un client de façon automatique.
Construire une API qui interrogera notre modèle
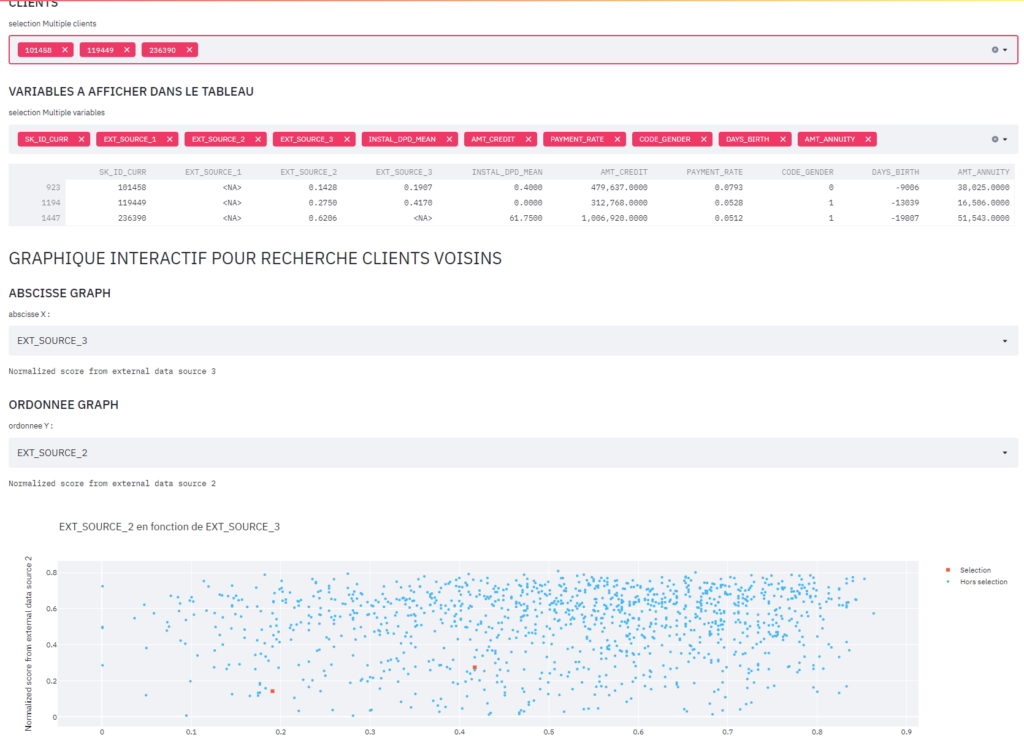
Construire un dashboard interactif à destination des gestionnaires de la relation client permettant d’interpréter les prédictions faites par le modèle et d’améliorer la connaissance client des chargés de relation client.
Déroulement du projet
Ce projet est le plus long de la formation car beaucoup de nouveaux concepts sont à assimiler.
Il faut commencer par gérer un jeu de données déséquilibrés, puis essayer différents modèles avec une métrique spécifique F2-score qui permet de minimiser les Faux négatifs (clients a qui on a prêté de l’argent et qui ne remboursent pas) pour la validation des modèles.
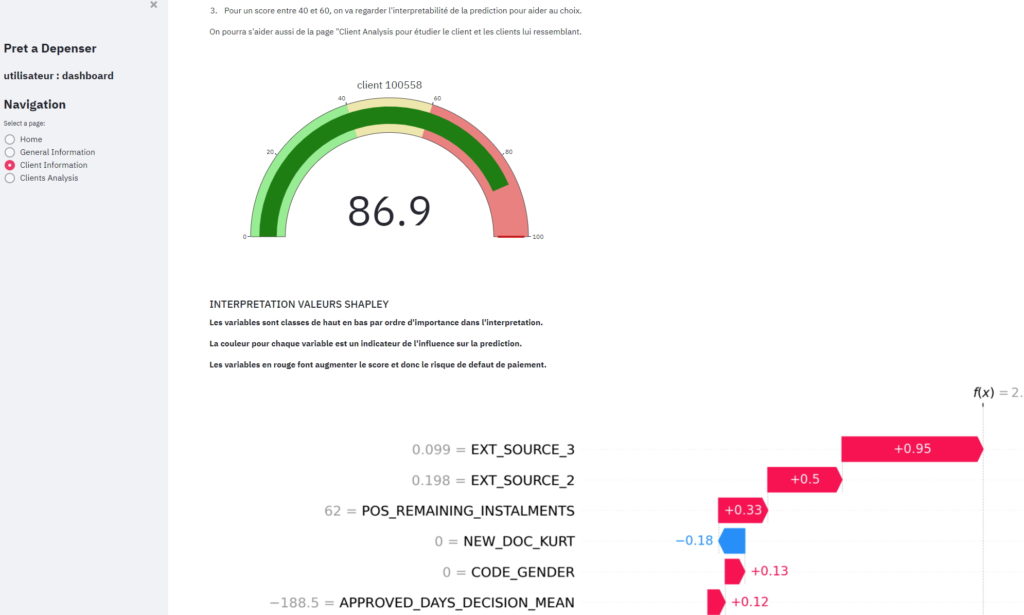
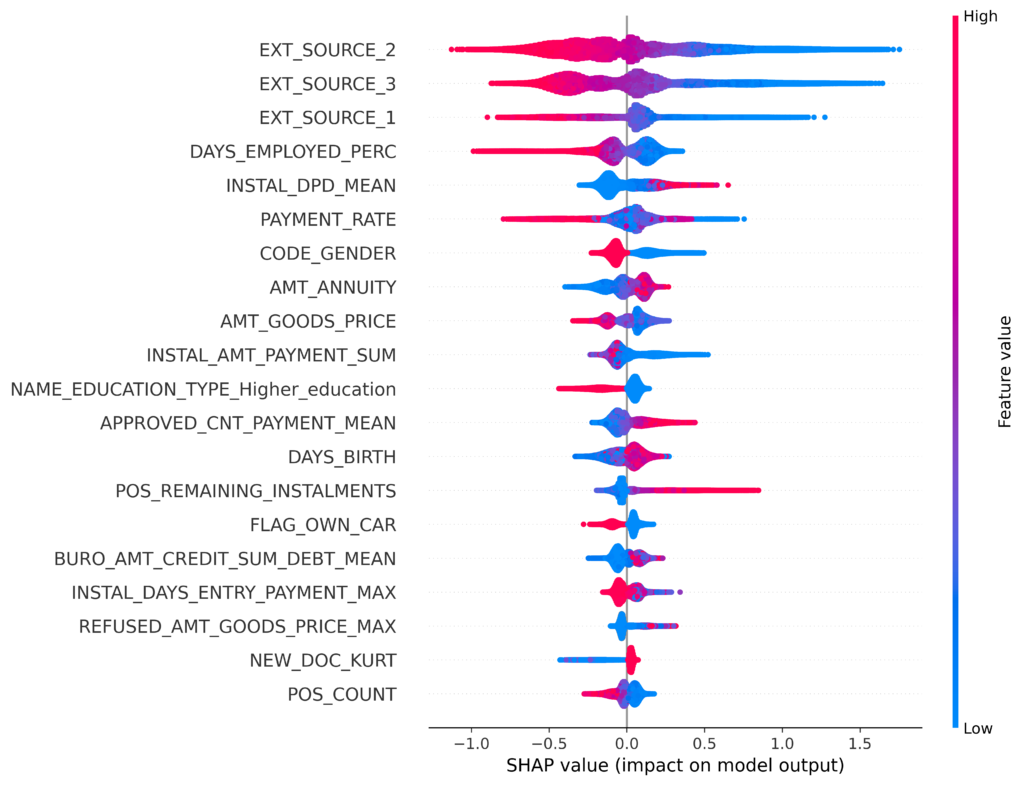
Pour l’interprétation des prédictions, j’ai utilisé les SHAPLEY values.
Le modèle retenu est basé sur LightGBM. J’ai alors sérialisé le modèle et les Shapley Values pour réutilisation dans l’API et le Tableau de bord.
L’API est de type REST déployé sur HEROKU.
Pour le Tableau de bord j’ai utilisé STREAMLIT qui permet d’avoir des graphiques interactifs
Compétences acquises
Présenter son travail de modélisation à l’oral
Déployer un modèle via une API dans le Web
Réaliser un dashboard pour présenter son travail de modélisation
Rédiger une note méthodologique afin de communiquer sa démarche de modélisation
Utiliser un logiciel de version de code pour assurer l’intégration du modèle